Indexes
Indexes are database structures that improve query performance by allowing the database to find and retrieve data faster. Think of an index like a book's index-instead of scanning every page to find a topic, you can jump directly to the relevant pages.
Why Use Indexes?
Without indexes, the database must scan every row in your table to find matching records, which becomes increasingly slow as your table grows. Indexes provide several key benefits:
- Faster Query Performance: Retrieve data in milliseconds, especially for large tables with millions of rows.
- Efficient Filtering: Speed up searches on columns you frequently filter by in your workflows or in Tables filters.
- Improved Sorting: Accelerate queries that sort data by specific columns.
- Better User Experience: Reduce loading times for table views and workflow executions.
Create indexes on columns that you frequently use in:
- Tables activity filters
- Tables UI searches
- Sorting operations
- Join conditions with other tables
Creating an Index
You can create indexes on single columns or multiple columns (composite indexes) to optimize different types of queries.
Single Column Index
To create an index on a single column:
-
Open your table and navigate to the Indexes tab
-
Click Add Index
-
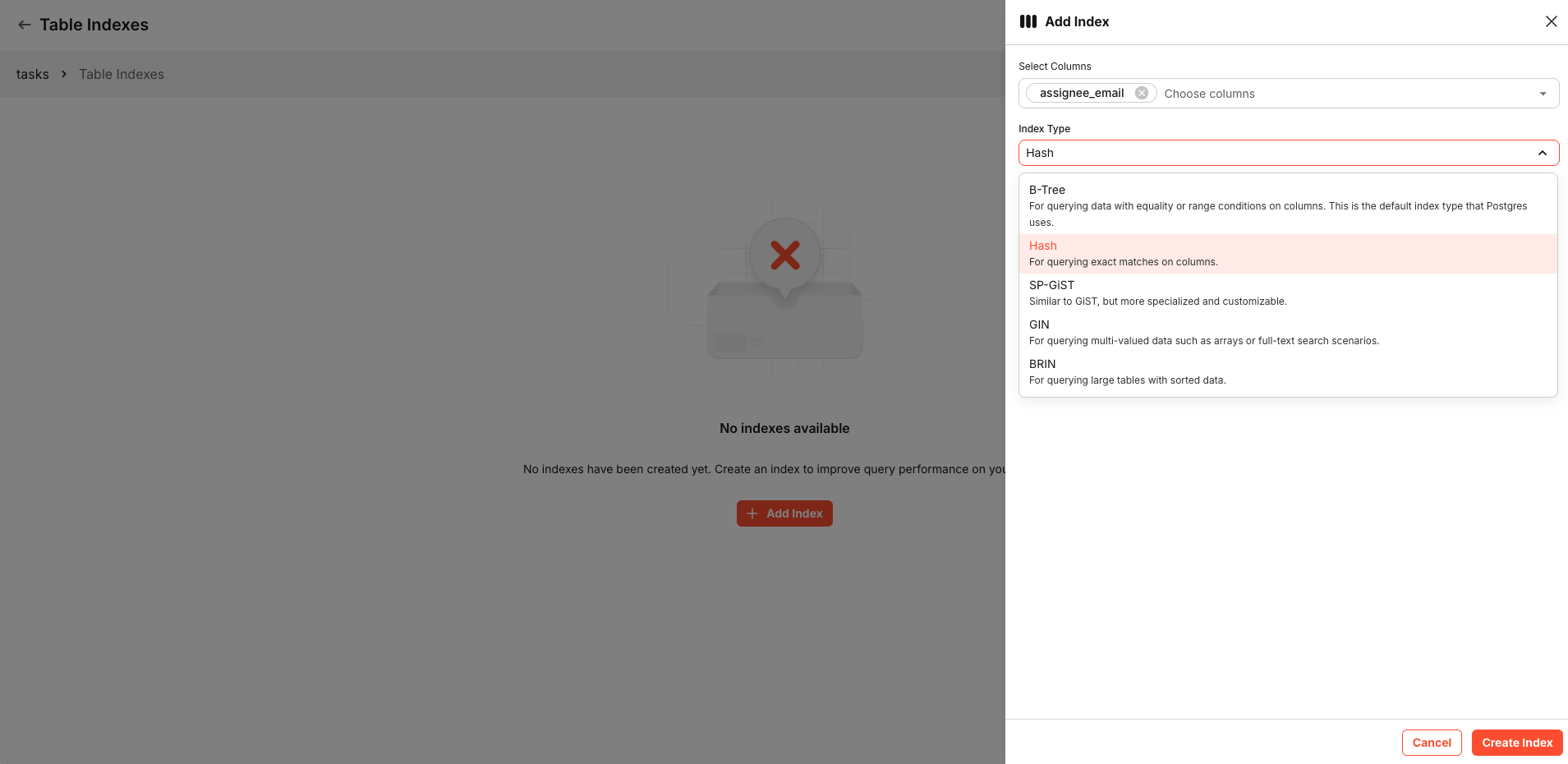
Select the column you want to index and choose an appropriate index type
-
Click Create Index
Composite Index
You can create indexes that span multiple columns too. This is useful when you frequently filter or sort by multiple columns together.
-
To create a composite index, select columns in the order you want them indexed
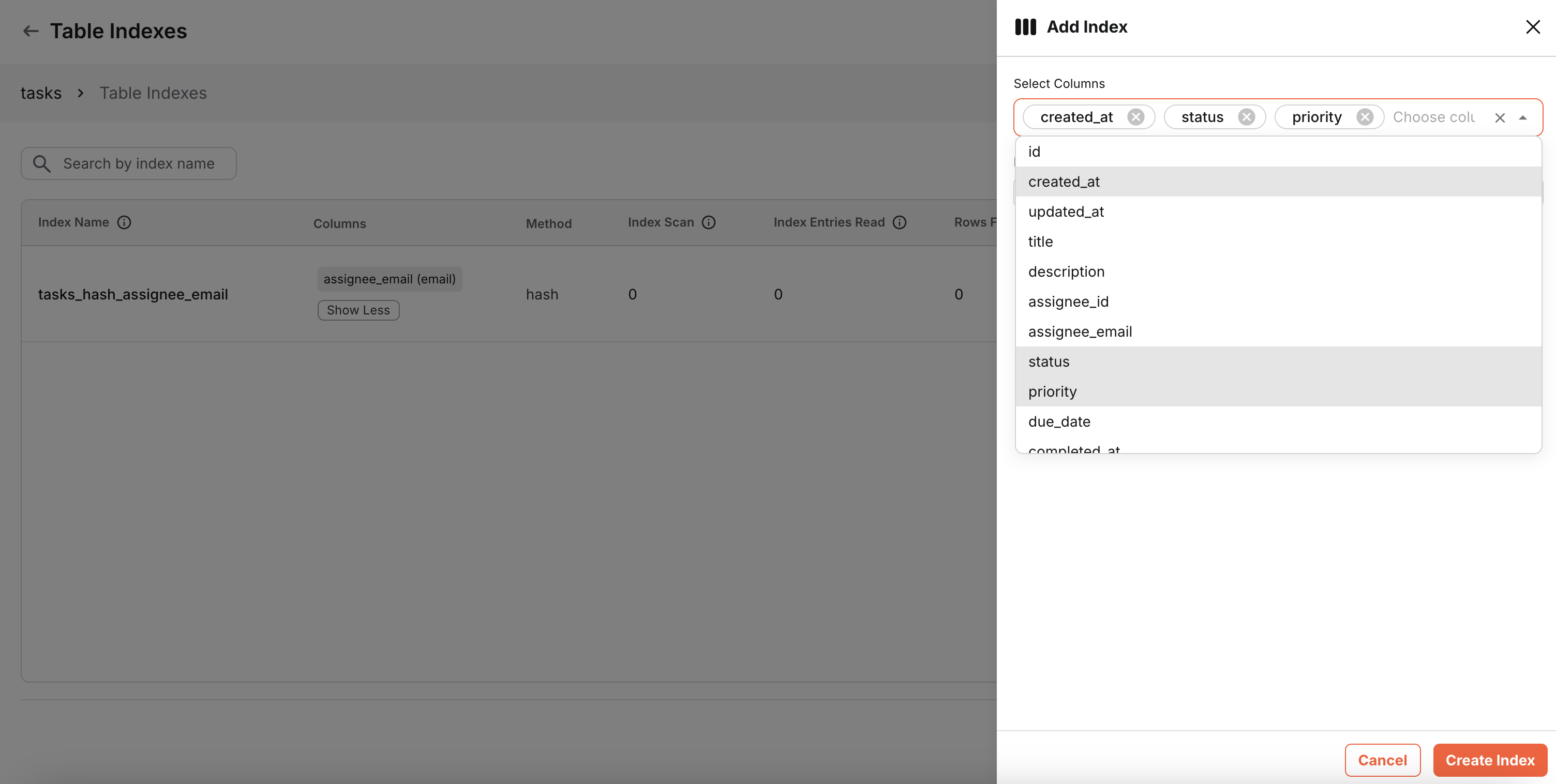
-
Choose an appropriate index type based on data type and index compatibility for the composite index
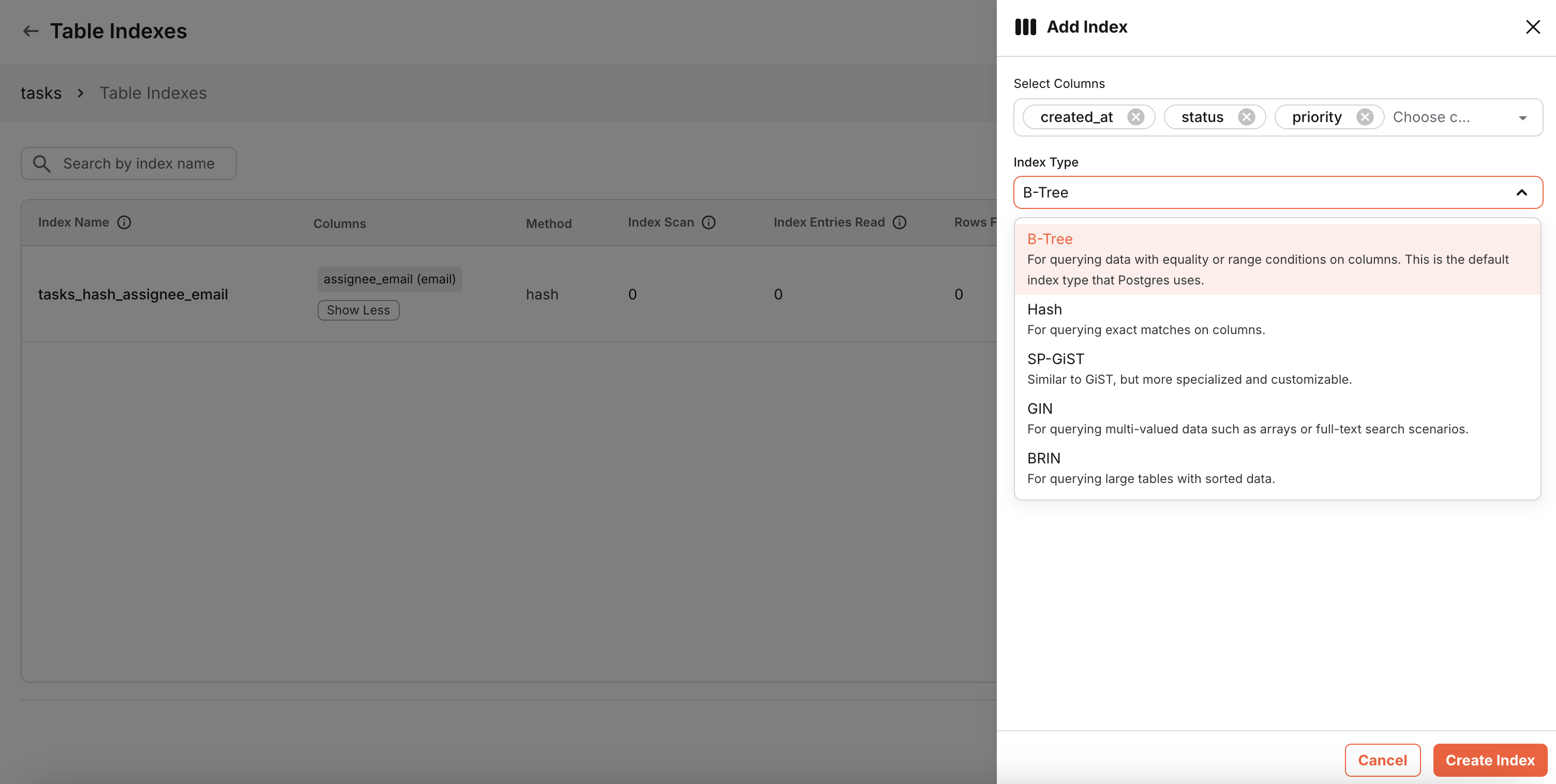
-
Click Create Index
The order of columns in a composite index is crucial for performance. The index is most effective when your queries filter or sort by columns in the same order as defined in the index.
Example: If you create an index on [status, created_at, priority], it will efficiently handle filters like:
status = 'active'status = 'active' AND created_at > '2024-01-01'status = 'active' AND created_at > '2024-01-01' AND priority = 'high'
But it will be less effective for:
created_at > '2024-01-01'(doesn't use first column)priority = 'high'(doesn't use first columns)
Index Methods
Fynd Boltic Database supports multiple indexing algorithms, each optimized for different data patterns and query types. Here are the available index methods:
B-Tree
B-Tree is the most versatile and commonly used index type. It efficiently handles queries with equality comparisons (=), range comparisons (<, >, <=, >=, BETWEEN), and sorting (ORDER BY).
-
Best for: Equality and range queries, sorting operations
-
Use when: You need general-purpose indexing for most data types and query patterns.
Hash
Hash indexes are optimized for simple equality lookups but cannot handle range queries or sorting. They can be slightly faster than B-Tree for pure equality checks on large datasets.
-
Best for: Exact equality matches only
-
Use when: You only perform exact match queries (e.g., looking up records by ID).
-
Limitation: Hash indexes do not support multi-column indexes.
GIN (Generalized Inverted Index)
GIN indexes are designed for columns containing multiple values, such as dropdown multi-select columns.
-
Best for: Multi-valued data like dropdowns and full-text search
-
Use when: You have dropdown columns with multi-select enabled.
SP-GiST (Space-Partitioned Generalized Search Tree)
SP-GiST is useful for specialized searches, particularly prefix matching on text columns (e.g., LIKE 'abc%' queries).
-
Best for: Non-balanced data structures, prefix searches
-
Use when: You frequently search by text prefixes or work with hierarchical data.
-
Limitation: SP-GiST does not support multi-column indexes.
BRIN (Block Range Index)
BRIN indexes are extremely compact and work well on huge tables where data is physically sorted or clustered (e.g., timeseries data stored in tables).
-
Best for: Very large tables with naturally sorted data
-
Use when: You have large tables with sequential data like date-time or IDs, and you perform range queries.
Data Type and Index Compatibility
Not all index methods work with all data types. Here's a compatibility matrix to help you choose the right index type:
| Data Type | B-Tree | Hash | SP-GiST | GIN | BRIN |
|---|---|---|---|---|---|
| Text | ✓ | ✓ | ✓ | ✗ | ✓ |
| Long Text | ✓ | ✓ | ✓ | ✗ | ✓ |
| Date & Time | ✓ | ✓ | ✗ | ✗ | ✓ |
| Number | ✓ | ✓ | ✗ | ✗ | ✓ |
| Currency | ✓ | ✓ | ✗ | ✗ | ✓ |
| Dropdown | ✓ | ✓ | ✗ | ✓ | ✗ |
| ✓ | ✓ | ✓ | ✗ | ✓ | |
| Checkbox | ✓ | ✓ | ✗ | ✗ | ✗ |
| Phone Number | ✓ | ✓ | ✓ | ✗ | ✓ |
| Link | ✓ | ✓ | ✓ | ✗ | ✓ |
| JSON | ✗ | ✗ | ✗ | ✗ | ✗ |
| Vector | ✓ | ✗ | ✗ | ✗ | ✗ |
| Sparse Vector | ✓ | ✗ | ✗ | ✗ | ✗ |
| Half Vector | ✓ | ✗ | ✗ | ✗ | ✗ |
| ID | ✓ | ��✓ | ✗ | ✗ | ✓ |
| Encrypted | ✓ | ✓ | ✗ | ✗ | ✓ |
Multi-Column Index Support
When creating composite indexes, different index methods have varying levels of support:
| Index Method | Multi-Column Support |
|---|---|
| B-Tree | Supports any combination of: Text, Long Text, Date & Time, Number, Currency, Dropdown, Email, Checkbox, Phone Number, Link, Vector, Sparse Vector, Half Vector, ID, and Encrypted |
| Hash | Does not support multi-column indexes |
| GIN | Limited to Dropdown columns only |
| SP-GiST | Does not support multi-column indexes |
| BRIN | Supports combinations of: Text, Long Text, Date & Time, Number, Currency, Email, Phone Number, Link, ID, and Encrypted |
Suggested Index Types by Use Case
Choose the optimal index type based on your query patterns:
| Column Type | Query Pattern | Recommended Index |
|---|---|---|
| Text / Email / Phone / Link | Exact match or prefix | B-Tree |
| Long Text | Substring or full-text search | GIN |
| Number / Currency | Equality and range | B-Tree |
| Dropdown | Single or multi-select | B-Tree (single) or GIN (multi) |
| Checkbox | Equality | B-Tree |
| Date & Time | Equality and range | B-Tree |
| Date & Time | Large append-only tables | BRIN |
| Large text | Prefix-only search (LIKE 'abc%') | SP-GiST |
| Exact match on UUIDs or large text values | Exact match only | Hash |
| Vector / Sparse Vector / Half Vector | Similarity search | HNSW |
| Encrypted | Equality lookups on deterministic data | B-Tree |
Index Limits
Each table can have up to 20 indexes. This limit ensures optimal performance and prevents excessive index maintenance overhead. Choose your indexes carefully based on your most common query patterns.
For Vector, Sparse Vector, and Half Vector columns, it is recommended to create HNSW indexes directly from the Add/Edit Column widget rather than from the Indexes tab. HNSW (Hierarchical Navigable Small World) indexes are specifically optimized for vector similarity searches and provide better performance for vector operations.
Understanding ID Column Indexes
The ID column has specific index behavior depending on the filter operators you use:
B-Tree Index on ID Column:
- Works with relational operators:
=,!=, Between,<,>,<=,>= - Does NOT work with: Contains (case-insensitive
ILIKE), Case-sensitive Contains (LIKE), and Starts With (LIKE 'abc%'`) operators
Hash Index on ID Column:
- Works with:
=only
For ID columns, B-Tree is recommended as it supports a wider range of filter operators. Use Hash only if you exclusively filter by exact ID matches and never use range queries or inequalities.
Viewing Indexes
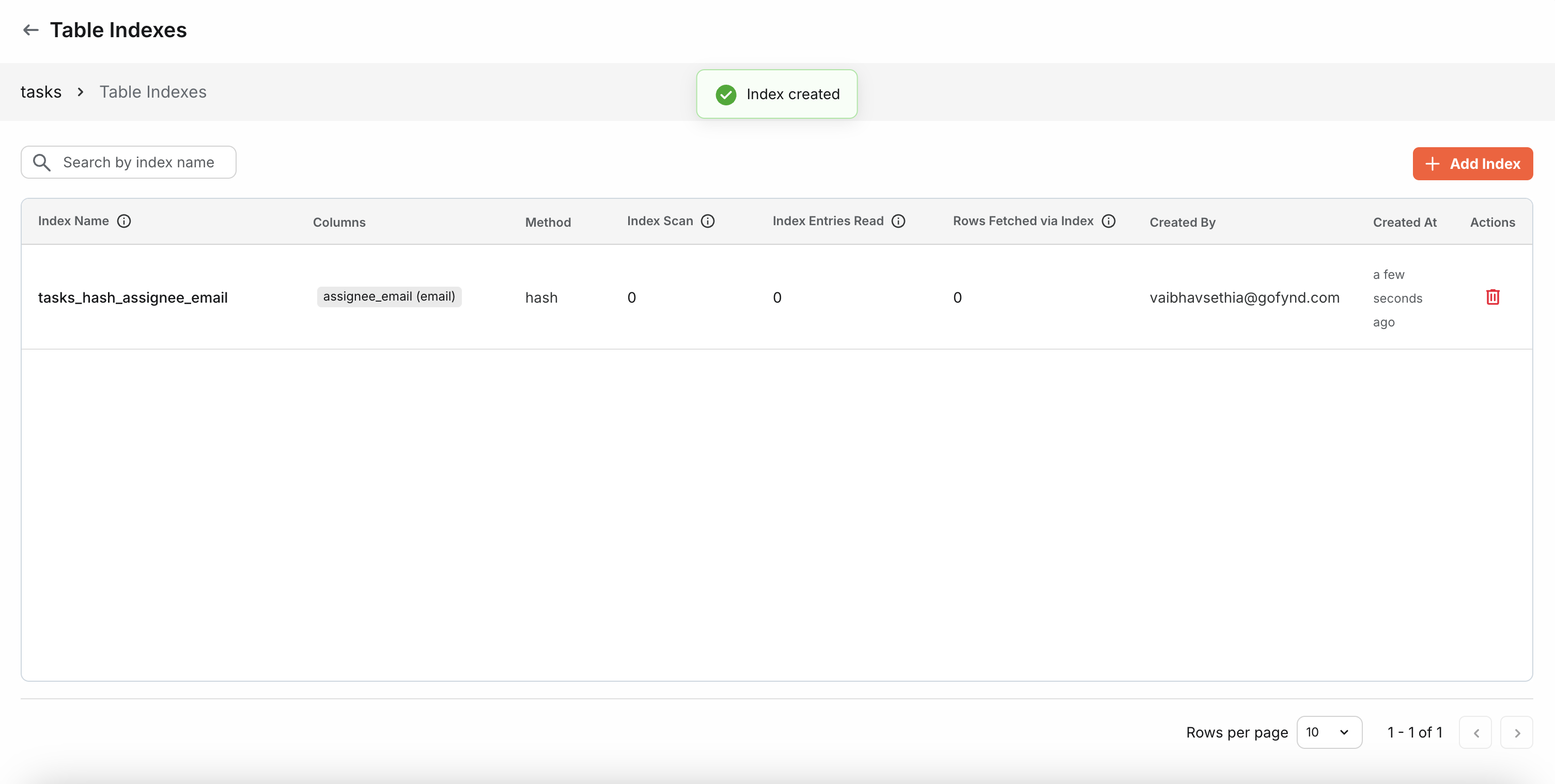
You can view all indexes created on your table from the Indexes page. The index list provides detailed information about each index's structure and performance.
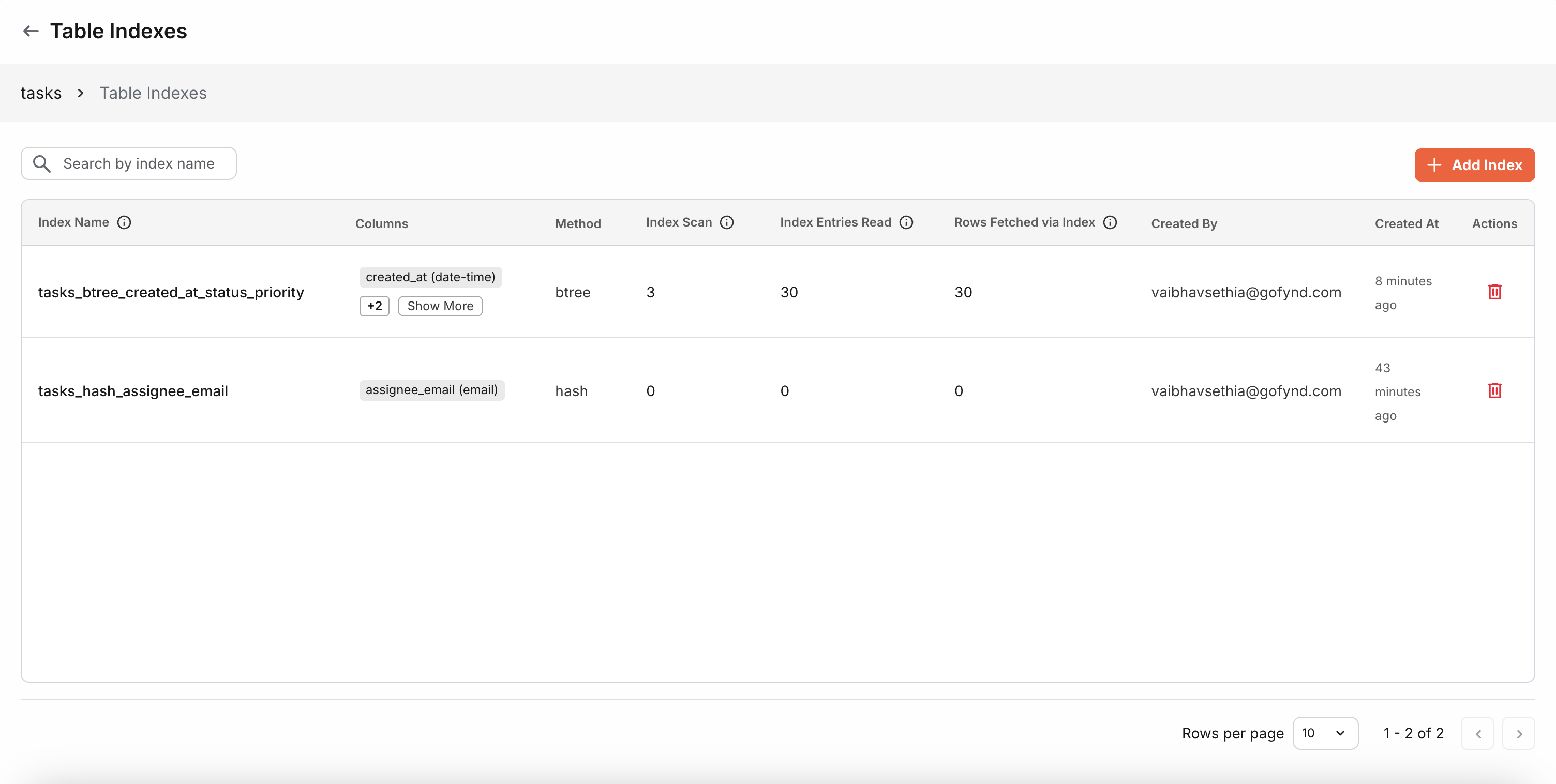
Understanding Index Metrics
Each index displays several performance metrics to help you understand its usage and effectiveness:
-
Index Scan - The number of times this index was used in queries. A higher number indicates the index is actively helping query performance. If this value is near zero, the index may be unused or redundant.
-
Index Entries Read - The total number of index entries examined during scans. This shows how much work the database does when using this index. Higher values indicate the index is being actively consulted, but very high values compared to Index Scan might suggest inefficient queries.
-
Rows Fetched via Index - The number of actual table rows retrieved using this index. This represents how many records were successfully located and returned through the index. This should generally correlate with your query result sizes. If significantly lower than Index Entries Read, it might indicate the index is examining many entries but returning few results.
Deleting an Index
You can delete indexes that are no longer needed or are not being used. However, exercise caution as this can significantly impact performance.
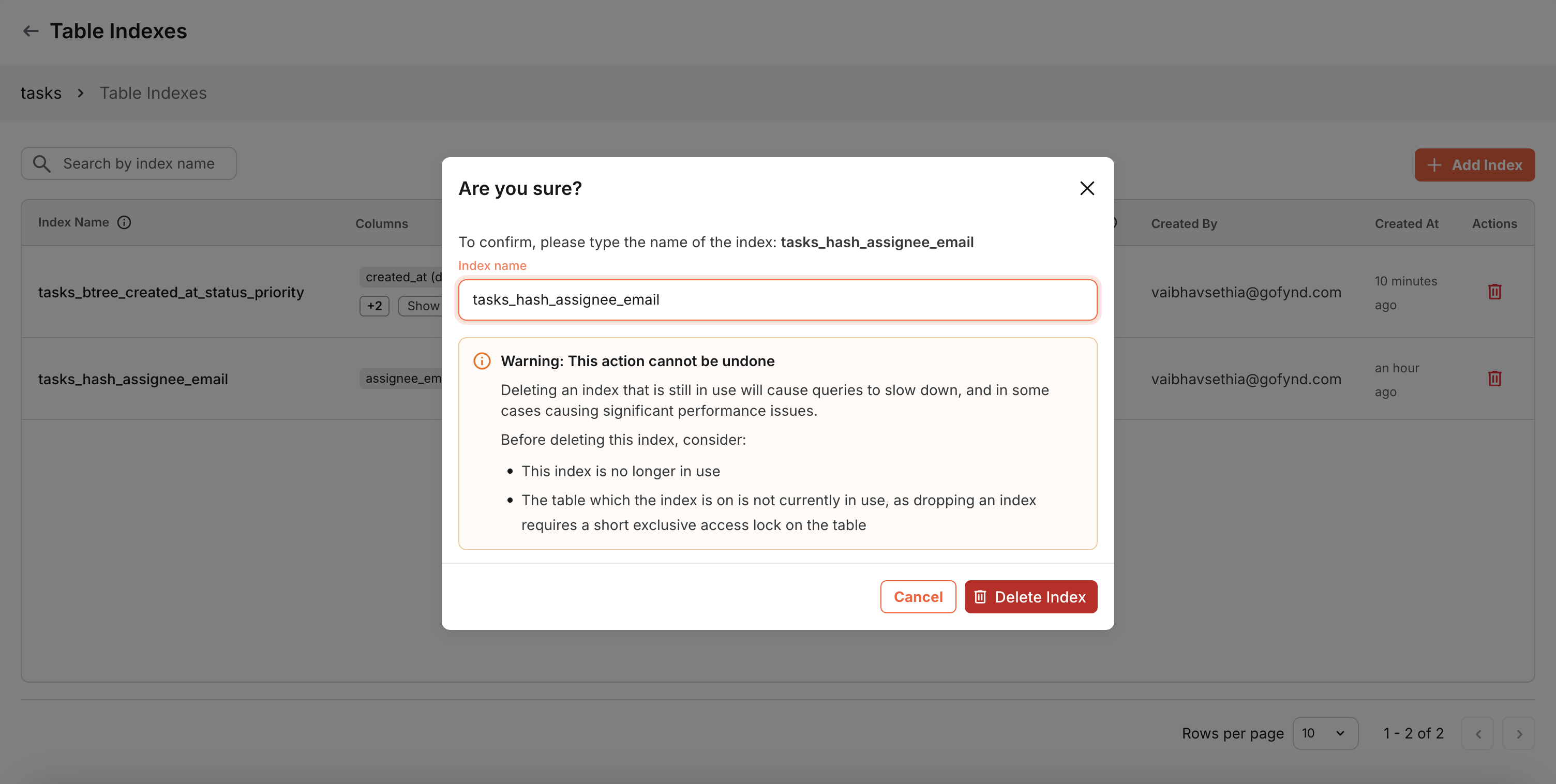
Deleting an index can severely impact performance for:
- Workflows: Any workflow using the indexed columns in conditions will run slower
- Tables: Table filters that rely on the indexed columns will become slower
- Query Performance: All queries that previously benefited from the index will revert to full table scans
Before deleting an index, verify:
- The index has very low or zero Index Scan count (indicating it's not being used)
- No active workflows depend on fast queries using those columns
Troubleshooting
| Issue | Likely cause | Solution |
|---|---|---|
| Index is not being used | Unsupported operators (e.g., ILIKE/LIKE/Starts With on ID), wrong index type, composite order mismatch, type incompatibility, or index still building | Use supported operators or Suggested Index Types. Ensure filters follow left-prefix order. |
| Queries are still slow after adding index | Index Scan count 0/low; index used but ineffective; table too small; query returns too many rows; multiple filters on different columns | Verify Index Scan metric and make queries more selective or you can create a composite index for columns filtered together. |
| Too many indexes slow down writes | Write overhead from maintaining many indexes | You can remove unused indexes, consolidate into composite indexes where appropriate, and keep only those that materially improve reads. |
Best Practices
Do's ✓
- Create indexes on columns frequently used in WHERE clauses, JOIN conditions, and ORDER BY statements
- Monitor index usage metrics regularly and remove unused indexes
- Use composite indexes when you frequently filter by multiple columns together
- Place the most selective (highest cardinality) columns first in composite indexes
- Create indexes on foreign key columns used in table relationships
Don'ts ✗
- Don't create indexes on every column; more indexes slow down INSERT and UPDATE operations
- Avoid indexes on columns with very low cardinality (e.g., checkbox columns with only two values)
- Don't duplicate indexes; check existing indexes before creating similar ones
- Avoid creating very wide composite indexes (5+ columns) unless absolutely necessary
- Don't forget to remove indexes when you change your query patterns or table structure
By understanding and properly utilizing indexes, you can ensure your Tables remain fast and responsive as your data grows. Start with indexes on your most queried columns, monitor their performance, and adjust as needed based on real usage patterns.