Pipe Creation Flow
Components of a Pipeline
- Source: The source represents the origin of your data. It can be a variety of data storage systems, including databases, SaaS-based applications (via API endpoints), or file storage. Fynd Boltic seamlessly integrates with popular data sources such as MongoDB, MySQL, and PostgreSQL.
- Destination: The destination is the target location where data from the source is loaded. It typically refers to a data warehouse or a database where you want to analyze and manage your data.
You can establish a connection between one source and one destination within a single Pipeline. However, multiple Pipes can load data into the same destination, allowing you to manage data from different sources effectively.
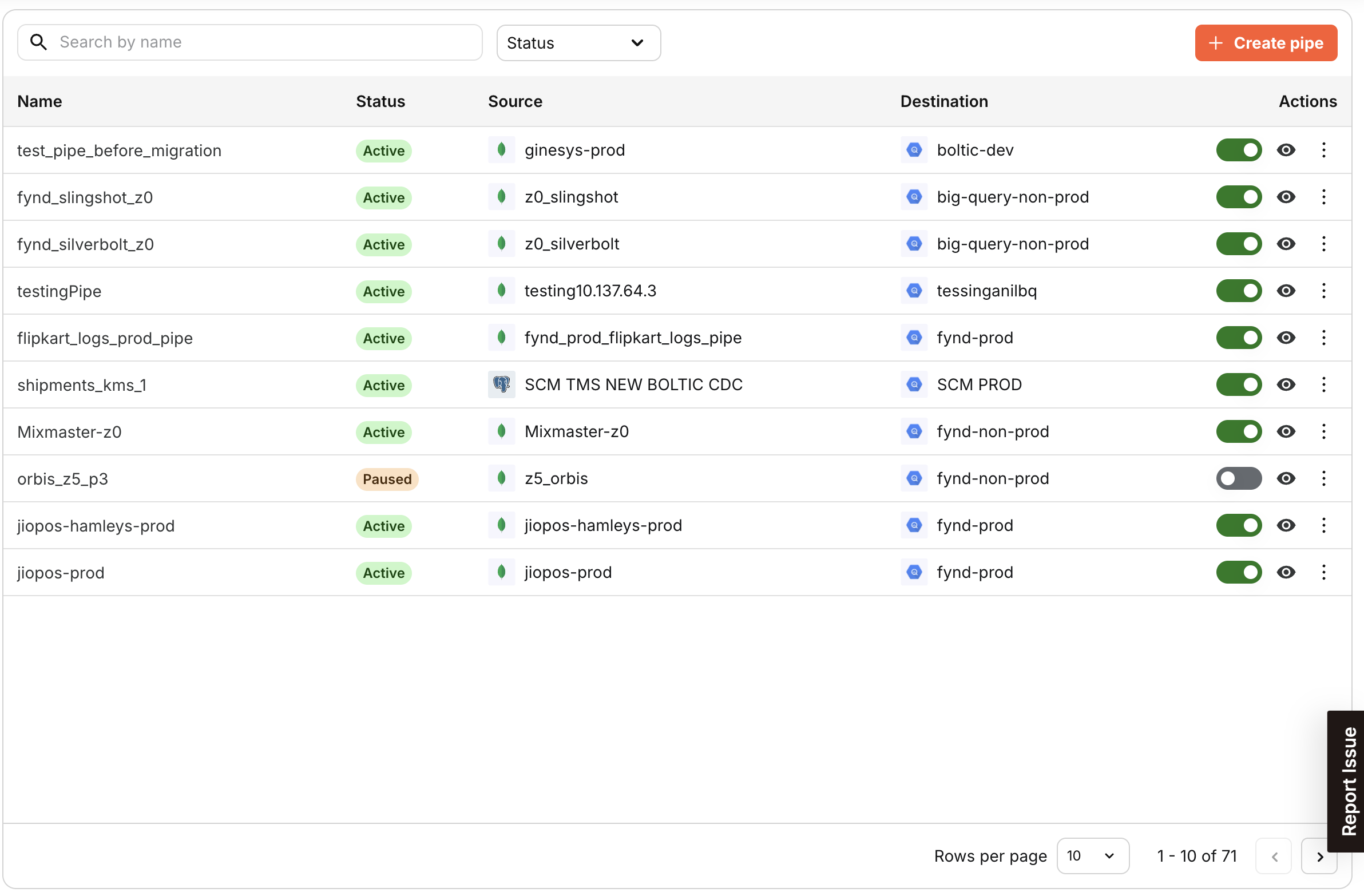
Pipe Listing - Managing Pipes
The Pipe listing page provides an overview of your created Pipes. On this page, you can perform the following actions:
- Search: Search pipes by their names
- Filtering: Filter Pipes by their status or integration type.
- Management: Create new Pipes or move existing Pipes to the trash.
Create a New Pipe
Let's walk through the process of creating a new Pipe, step by step:
- Configure Source
- Configure Destination
- Configure Settings
Step 1: Configure Source
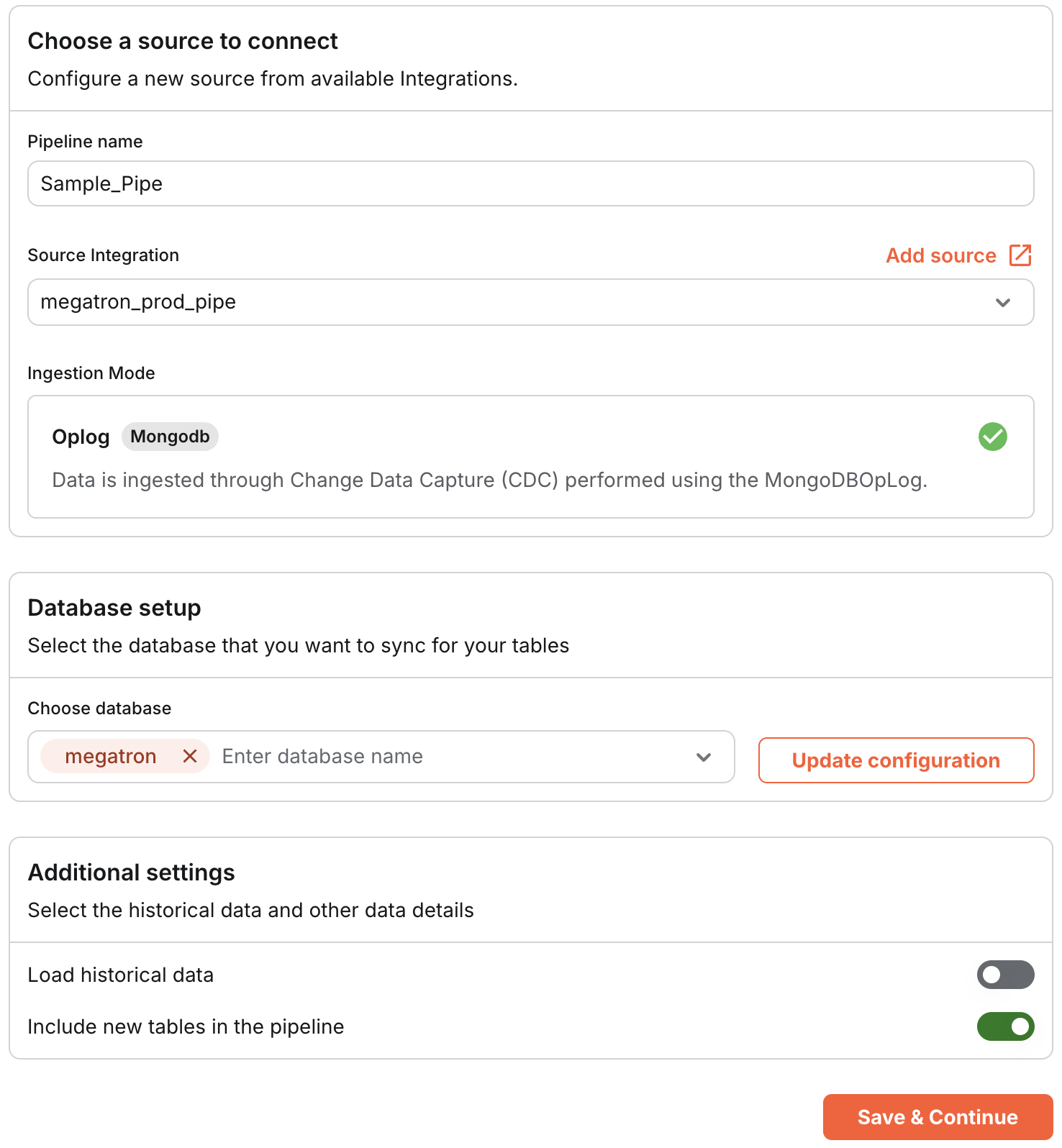
- Pipe Name: Give your Pipe a unique & meaningful name that represents its purpose.
- Connect Source Data: Choose an existing Integration (source) from which you want to retrieve your data.
- Source Configuration: Configure your source settings, such as loading all schemas or selecting specific databases. You can also choose to load historical data and include new tables in the pipeline.
- After configuring the source, click on 'Save & Continue' to proceed.
Failure Handling Mode
The Failure Handling Mode lets users decide how to handle errors like oversized documents or events during data processing:
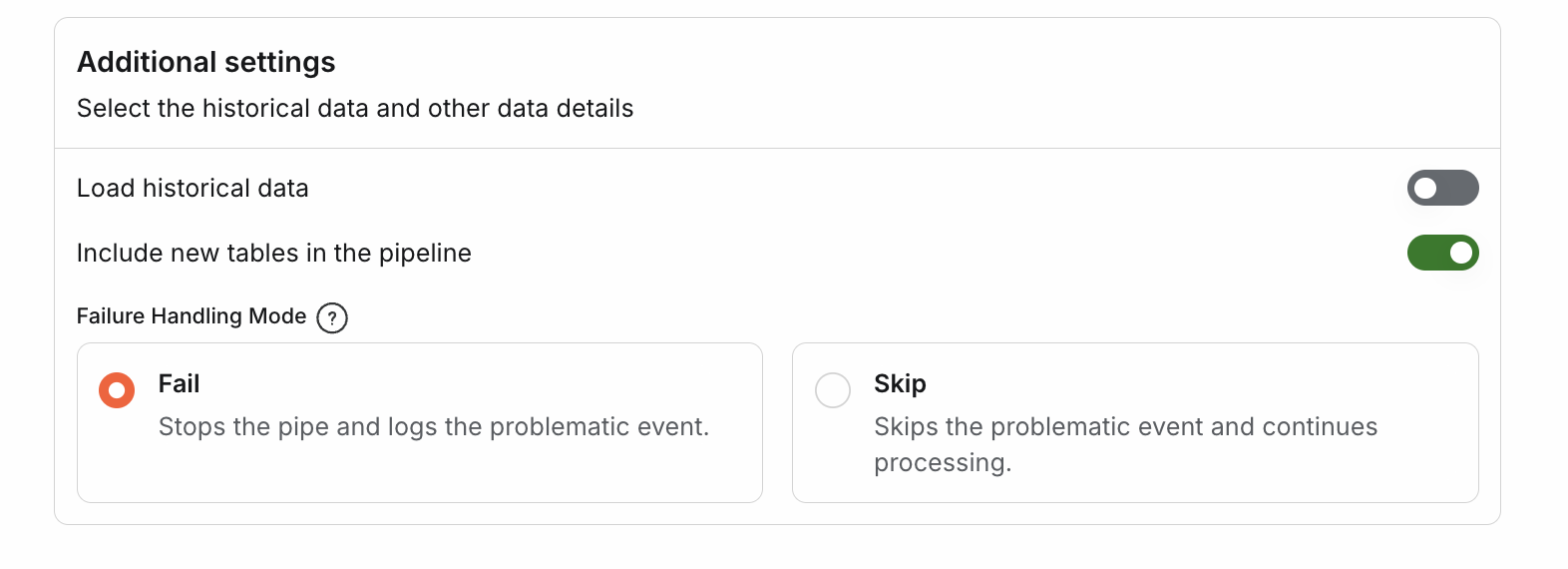
Skip: Logs the issue and continues processing the remaining data to avoid interruptions.
Fail: Stops processing and shows an error message to address the issue immediately.
Users can configure this option easily in the UI while creating a pipe. This feature provides clear control and ensures smooth data processing.
Step 2: Configure Destination
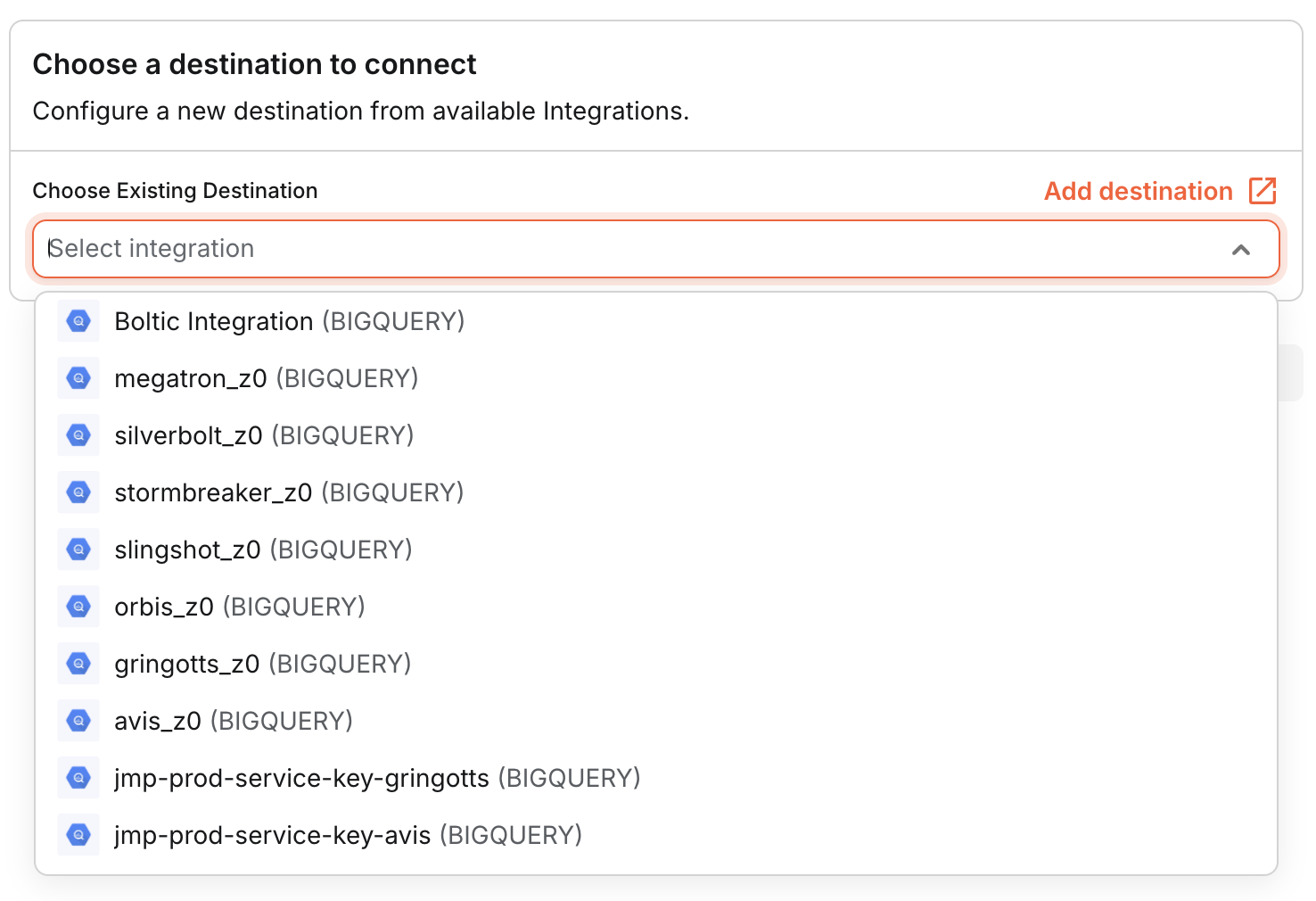
- Connect Destination: Choose an existing destination where you want to load your data.
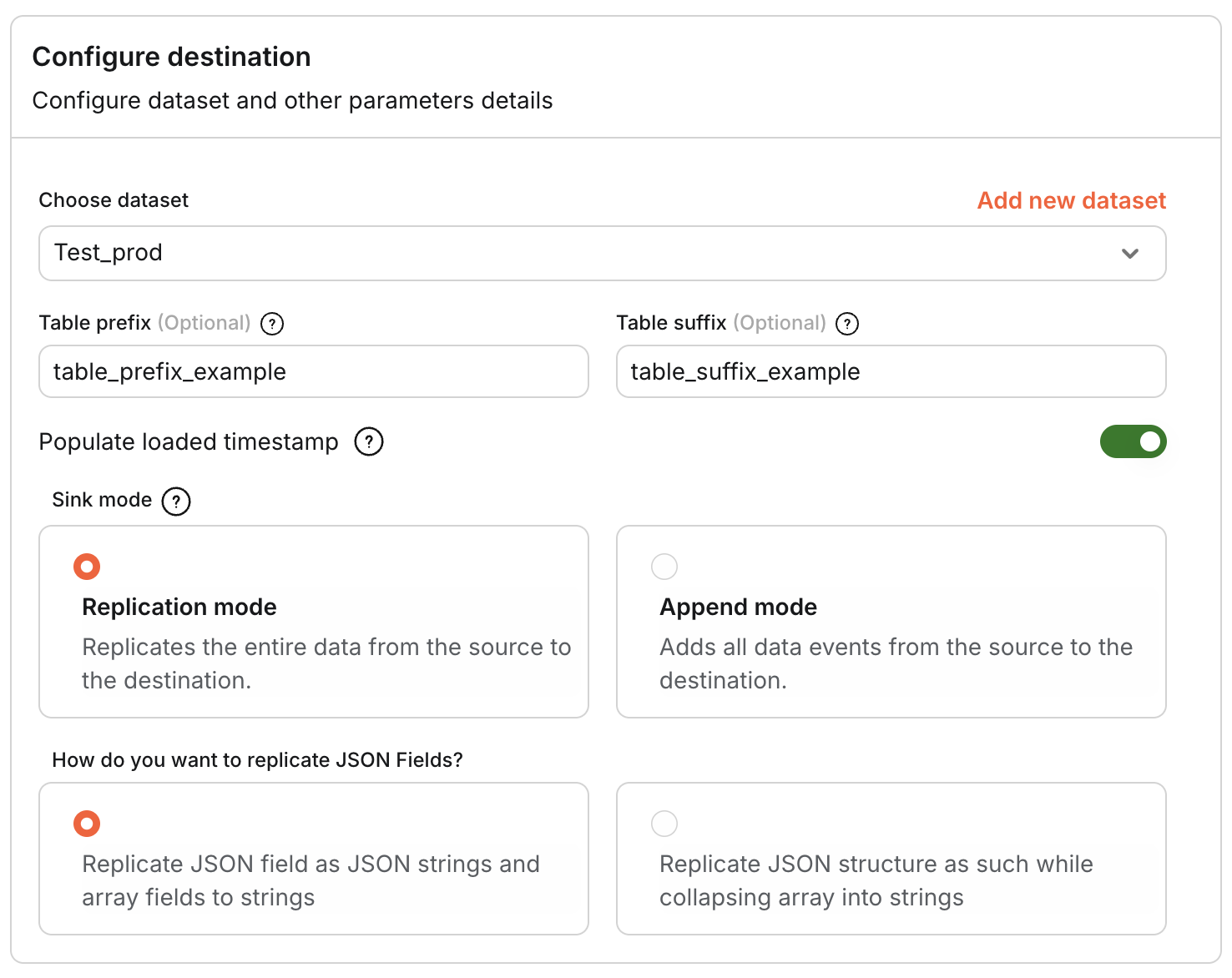
- Destination Configuration: Select an existing dataset or create a new one. If creating a new dataset, specify its name and region. Optionally, you can set a destination table prefix, which will be applied to your table names.
- Populate Loaded Timestamp: If desired, enable this option to include a timestamp indicating when the data was loaded.
- After configuring the destination settings, click on 'Save & Continue'.
Step 3: Connection Settings (Set up Connection)
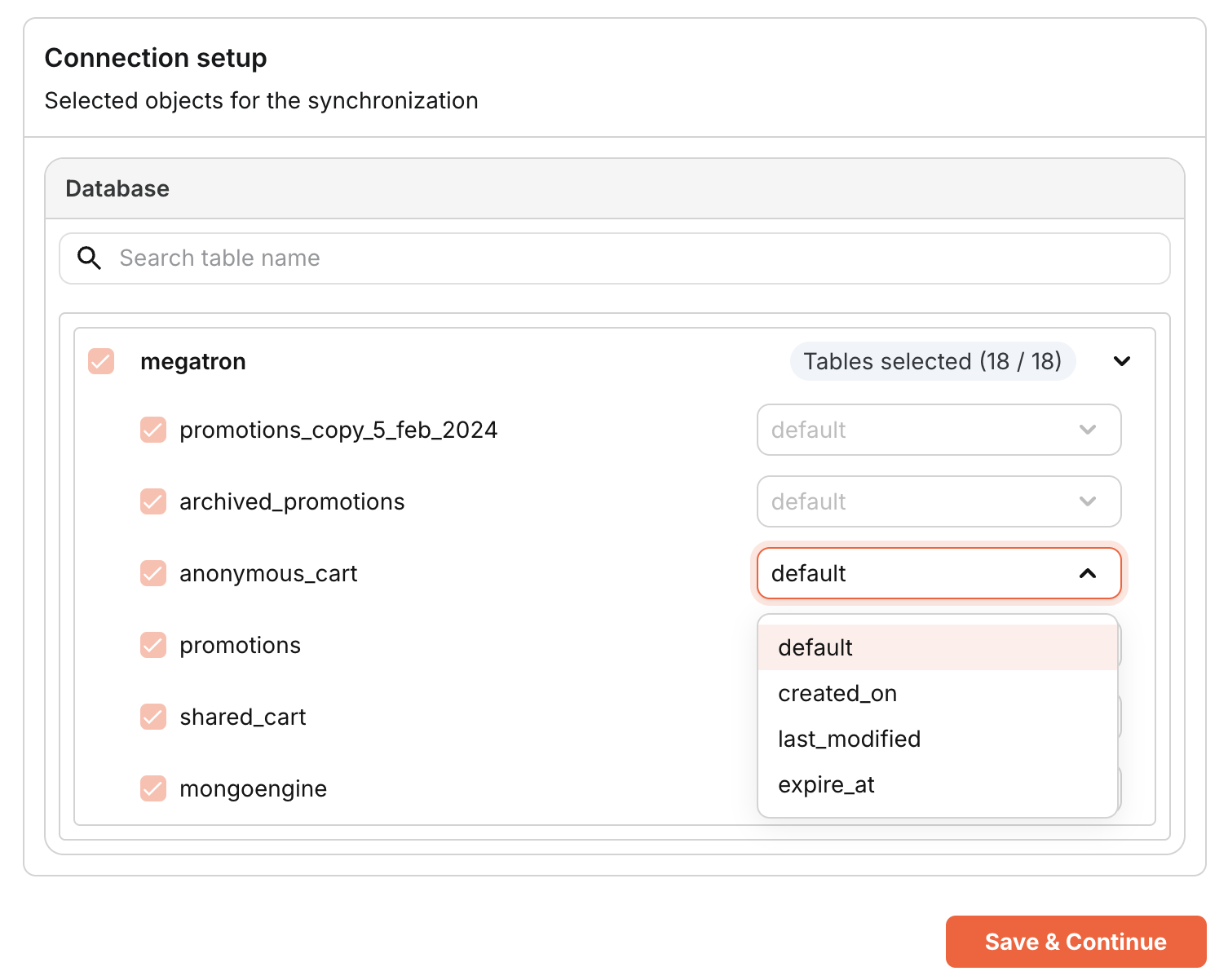
- Object Selection: Choose the specific objects (tables, collections, etc.) from the source that you want to synchronize.
- Partition Key: If available, specify a partition key for each object to optimize queries.
- After configuring the connection settings, click on 'Save & Continue'.
Step 4: Final Settings
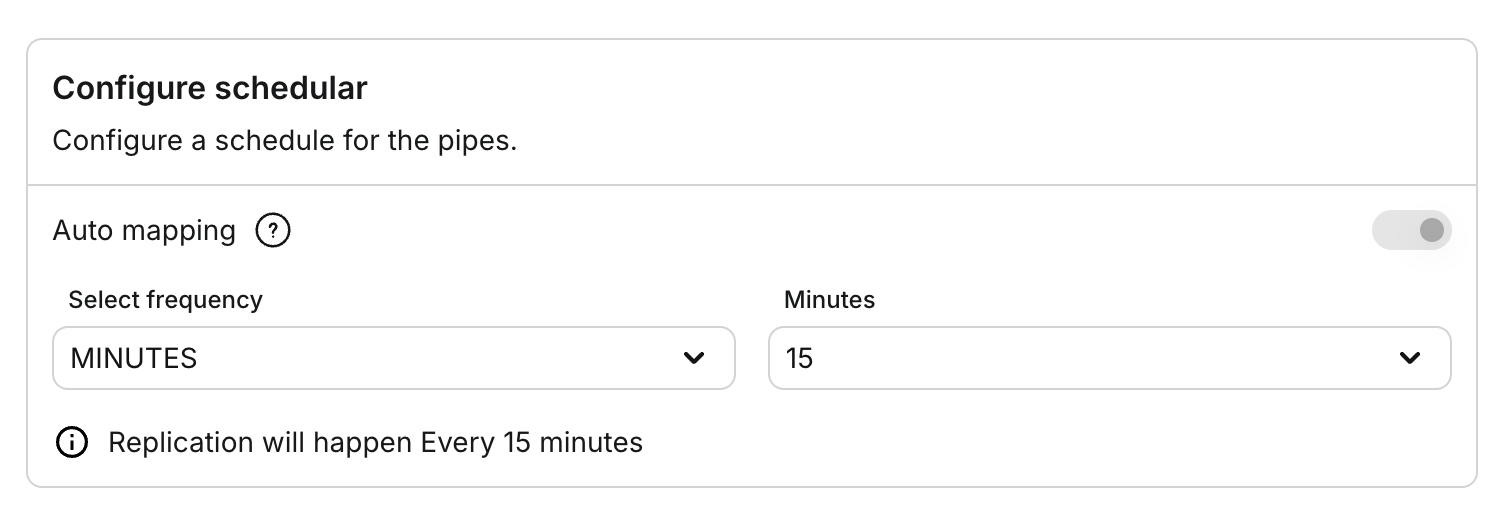
- Schema Mappings: Fynd Boltic automates schema mappings for your Pipe, simplifying the setup process.
- Replication Frequency: Choose the frequency at which data is synchronized, whether minutely, hourly, or daily.
- After configuring the final settings, click on 'Save & Deploy'.
Upon successful deployment, you'll be directed to the overview page of your new Pipe, where you can monitor its status and performance.
Pipe Overview
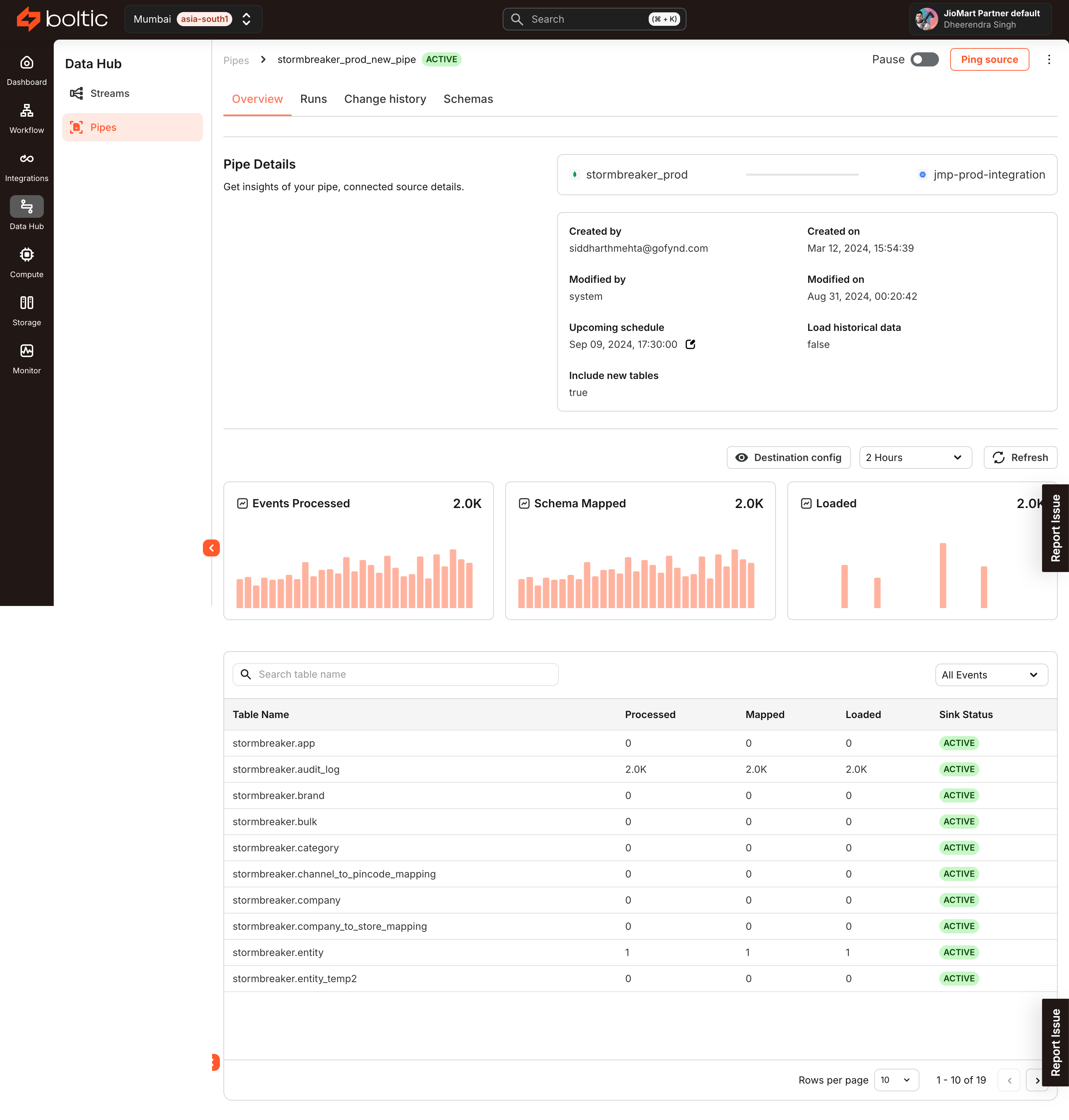
| Tab | Description |
|---|---|
| Overview | - View overall Pipe details including Status |
| - Pause or Resume the Pipe | |
| - See Upcoming Schedule | |
| - Track Events Processed | |
| - Check Schema Mapping | |
| - Monitor Loading and Historical Load Status | |
| - Check the Last Synced timestamp | |
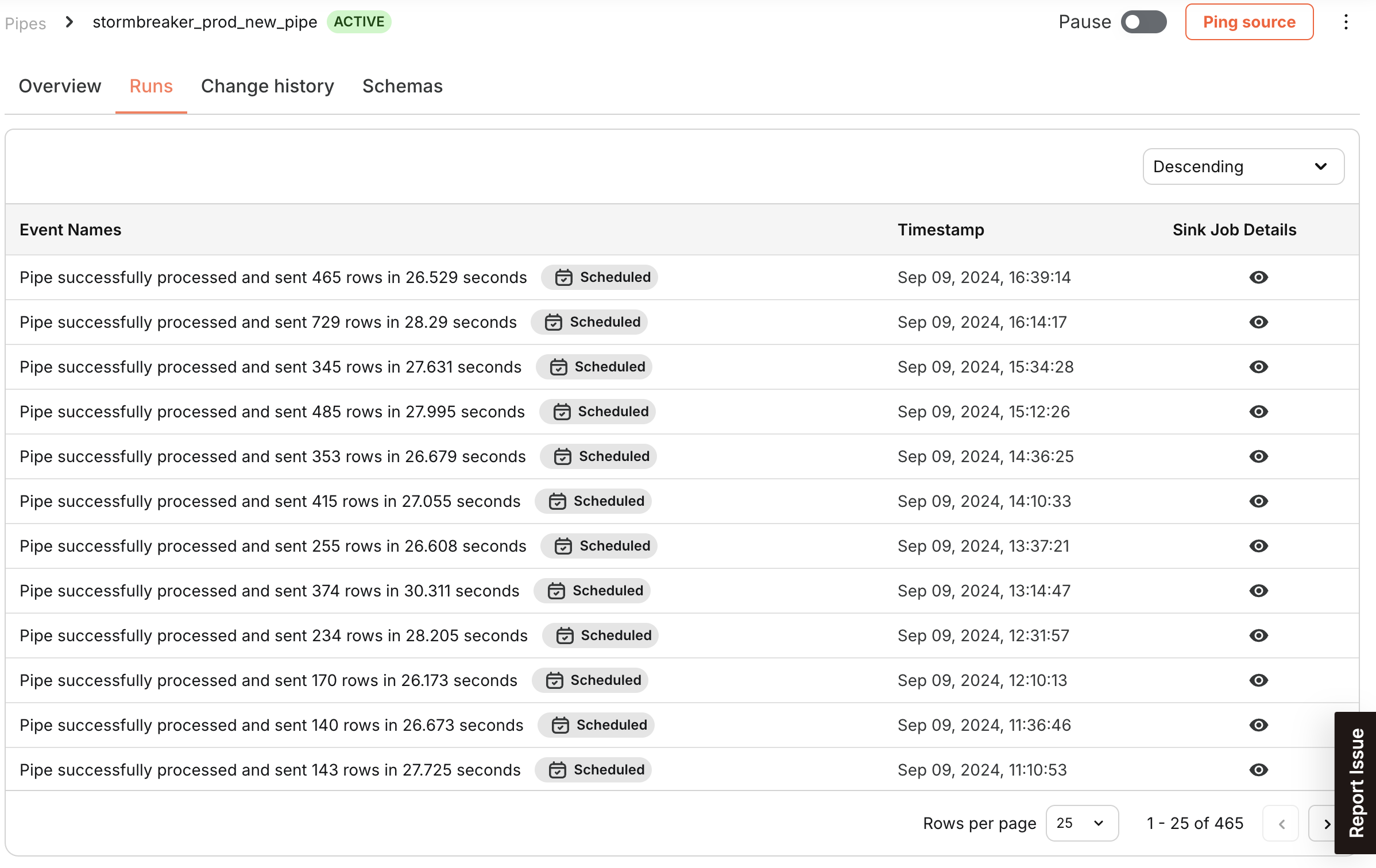
| Runs | - View history of Pipe processing and data sinking |
| - Monitor the processing status and history | |
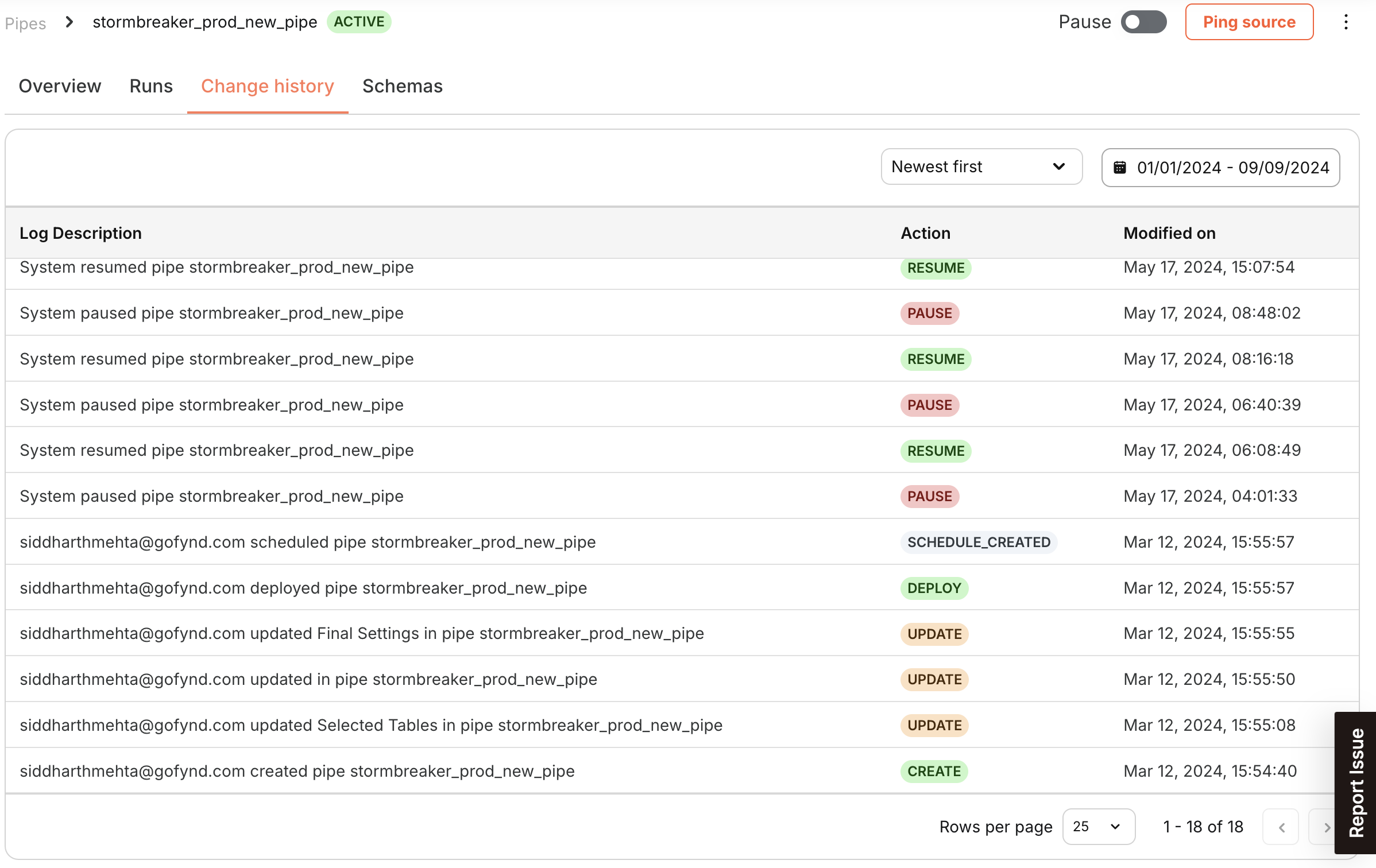
| Change History | - Check the audit trail and history of changes made to the Pipe configuration |
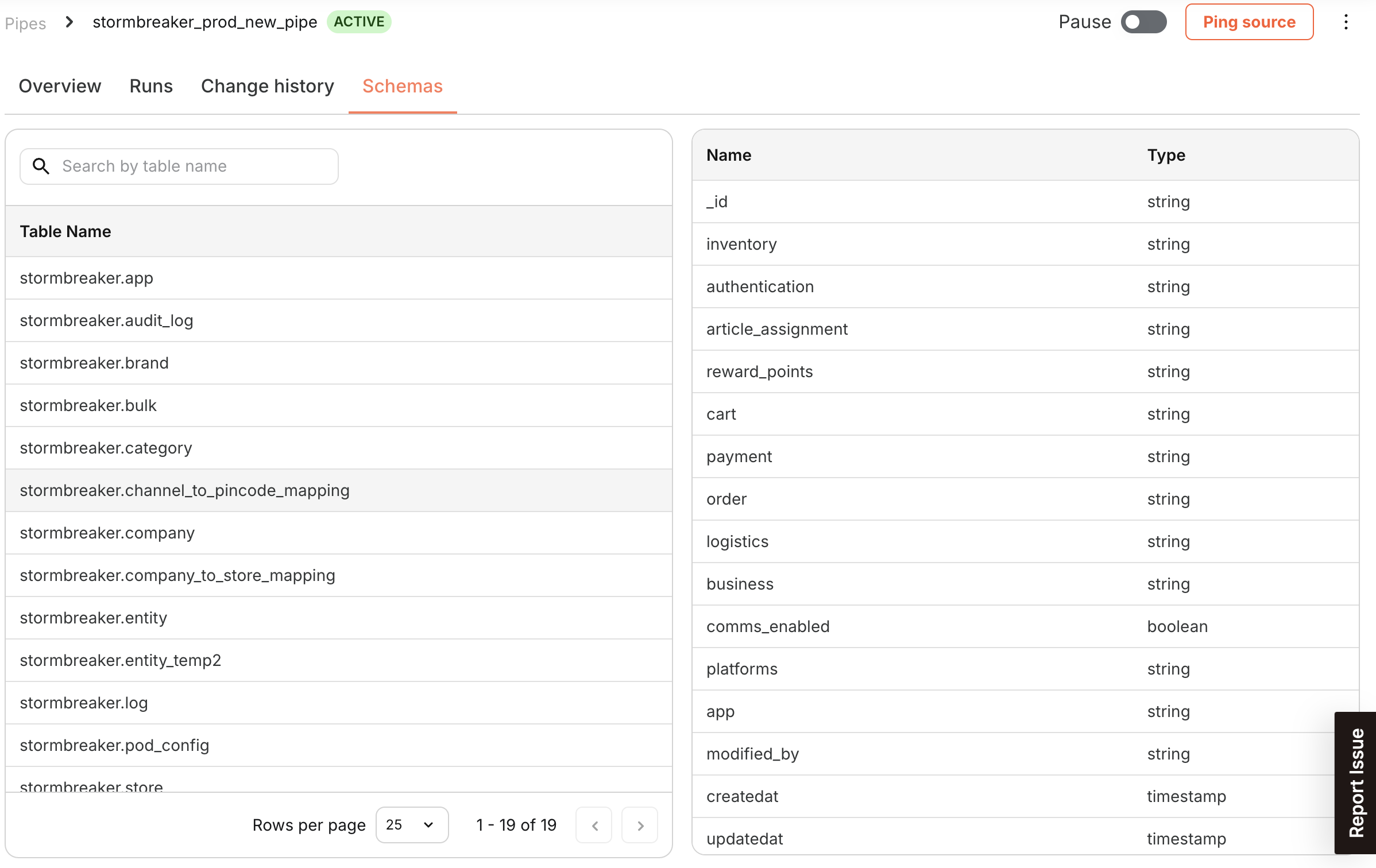
| Schemas | - Explore the schema of the Source data used in the Pipe |
| - Understand the structure of the data |
Runs
Change History
Pipe Schema